Jaula Tattoo: el mejor estudio de tattoos Valencia

¿Vives en Valencia y quieres disfrutar de un tatuaje bonito y de calidad? A lo largo de este artículo te vamos a mostrar cual es el mejor estudio de tattoos en Valencia para que puedas conocerlo y ...
LEER MAS +Cómo solicitar daños y perjuicios por humedades

Según los últimos estudios, las humedades es uno de los problemas más comunes en las viviendas y locales en nuestro país. A pesar de que cada vez se toman más medidas para que la aparición de las ...
LEER MAS +Tipos de implantes dentales y sus principales características
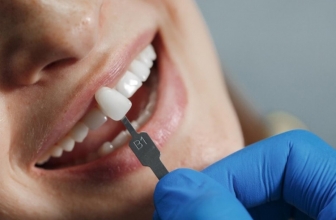
Los implantes dentales son como piezas especiales que se ponen en la boca para que funcione bien y también para que se vea bien. Hay muchos tipos diferentes en el mercado, lo que puede hacer difícil ...
LEER MAS +Diferencia entre audífono e implante coclear: ¿Qué me conviene más?
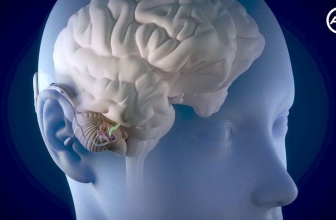
Si estás aquí es porque seguramente tienes un problema de audición y estás buscando el mejor remedio para conseguir mejorar la audición. Lo que está claro es que actualmente hay diferentes métodos ...
LEER MAS +¿Qué es el ciclo de vida del desarrollo del software?

Sabemos que pocas personas saben realmente qué es el ciclo de vida del desarrollo de software. Por ese motivo hemos decidido realizar con la colaboración de los expertos en dicho desarrollo en este ...
LEER MAS +Psicoterapeuta: ¿Qué es y cómo puede ayudarme?

Si buscas información sobre el psicoterapeuta, estás en el lugar indicado. Con la ayuda de nuestros expertos te vamos a mostrar qué es, cuáles son sus principales funciones y cómo puede ayudarte este ...
LEER MAS +Por qué SEAG es la mejor alternativa a un seguro de impago de alquiler

Los seguros de alquiler son una opción popular que ofrecen protección a los propietarios de una vivienda frente al impago del alquiler. Sin embargo, se trata de una póliza que, para ser ejecutada en ...
LEER MAS +Contenedores de obra y marítimos: usos y funcionalidades

¿Buscas información sobre los contenedores de obra y marítimos? Estás en el lugar indicado. Con la ayuda de nuestros expertos te vamos a dar toda la información que buscas. Nuestro objetivo es que ...
LEER MAS +Impresora de tarjetas Zebra: razones para apostar por esta marca

¿Estás pensando en comprar una impresora de tarjetas? Si quieres que la experiencia sea positiva a corto y largo plazo, una de las mejores opciones por las que puedes optar es por las impresoras de ...
LEER MAS +Cómo hacer una exitosa Transformación Digital según Marc Vidal

Si queremos intentar conocer cómo será el futuro, lo mejor que se puede hacer es escuchar las palabras de Marc Vidal. Él mismo ha explicado cómo será la transformación digital y eso nos ayuda a ...
LEER MAS +Tipos de audífonos para sordera

Explorar el mundo de los audífonos para sordera abre un abanico de opciones que pueden marcar la diferencia en la calidad de vida de quienes enfrentan problemas de audición. Desde modelos avanzados ...
LEER MAS +67 frases para centros funerarios

En momentos de pérdida, encontrar consuelo en palabras que honren y celebren la vida de un ser querido es fundamental. Las frases para centros funerarios juegan un papel crucial al expresar ...
LEER MAS +PADI o SSI: ¿Qué curso para buceo es mejor?

Sumergirse en el fascinante mundo del buceo es una decisión emocionante, pero a menudo surge la pregunta: ¿PADI o SSI? Ambas organizaciones son reconocidas internacionalmente y ofrecen cursos de ...
LEER MAS +¿Cuáles son los mejores productos para barba?

Si quieres disfrutar de una barba bonita, debes saber que los cuidados son fundamentales para que el aspecto sea el deseado. Algunas personas se dejan barba para evitar tener que afeitarse cada poco ...
LEER MAS +¿Bici aero o escaladora? Descubre en qué se diferencian

Hace años había muy poco que hablar sobre las bicicletas, pues prácticamente solo teníamos en mente comprar un modelo estándar o una versión de montaña. Según el uso o los gustos de cada usuario, se ...
LEER MAS +Cómo detectar mini cámaras espías

La tecnología no para de evolucionar y eso hace que cada vez estemos más vigilados. Cuando caminamos por las calles es normal encontrar cámaras de seguridad por casi todos los sitios. Esas cámaras no ...
LEER MAS +Qué audífono es mejor, Widex o Siemens

Los audífonos son prácticamente indispensables si tenemos un problema de hipoacusia. Con estos dispositivos tenemos la oportunidad de mejorar la percepción de los sonidos que nos rodean, aumentar su ...
LEER MAS +Tipos de motos y sus principales características

Aunque cuando hablamos de motos, siempre lo hacemos por un igual, la realidad es que hay motos para todo tipo de gustos y necesidades. Y para demostrártelo te vamos a mostrar uno de los diferentes ...
LEER MAS +Tipos de herramientas de sujeción: ¿Cuáles son?

A la hora de realizar algunos trabajos es importante apostar por las herramientas de sujeción. En más de un trabajo son útiles y permiten que el desarrollo del mismo sea más seguro y sobre todo ...
LEER MAS +Propiedades del dulce de membrillo que debes conocer

El membrillo es una fruta con una larga tradición, pues sabemos que ya era consumido por los antiguos griegos y los romanos. De hecho, las civilizaciones pasadas lo asociaban comúnmente con la ...
LEER MAS +Significado de los anillos en los dedos: ¿En qué dedo debo llevarlo?

¿Sabías que un anillo tiene un significado diferente dependiendo del dedo en el que lo lleves puesto? Pues sí, el significado puede cambiar según el dedo en el que lo lleves puesto. Por ese motivo, ...
LEER MAS +¿Qué alimentos pueden comer los conejos? Dudas más comunes

Si vas a adoptar un conejo tienes que tener claro que no solo lo tienes que cuidar, también lo tienes que alimentar. Una alimentación de calidad hará que tu mascota pueda ser feliz y en consecuencia ...
LEER MAS +Tipos de escape room según la temática

Los juegos de escape, popularmente conocidos como escape rooms, son una de las formas de entretenimiento más populares en la actualidad para hacer en grupos con familiares o ...
LEER MAS +¿Cuál es el consumo de un lavavajillas?

Son muchas las personas que nos han preguntado sobre el consumo del lavavajillas. Muchas de ellas para saber si realmente merece la pena comprarlo y otras para ver si merece la pena ponerlo. Al fin y ...
LEER MAS +Tipos de generadores y cuál es su aplicación ideal

¿Has oído hablar de los generadores y sus utilidades?, ¿sabías que existen diferentes tipos de ellos en el mercado actual? Los generadores se pueden aplicar en diferentes ámbitos según sus ...
LEER MAS +Tipos de siliconas para sellar

Si vas a realizar un trabajo que necesita de silicona, no debes cometer el error de usar la primera silicona que encuentres por casa. Debes tener claro que actualmente existen diferentes tipos de ...
LEER MAS +Suelo laminado o vinílico: pros, contras y cuál necesitas

Si estás pensando en cambiar el suelo, lo más seguro es que dos de las opciones que tienes en mente sean el suelo laminado y el vinílico. Las dos opciones pueden ser buenas, pero tomar una decisión ...
LEER MAS +Cómo funciona un simulador de ciclismo y cuál es el mejor del mercado

Los rodillos para bicicleta se han convertido en los mejores aliados de los ciclistas a la hora de hacer entrenamientos indoor. Estos interesantes dispositivos permiten pedalear sin impedimentos ...
LEER MAS +Requisitos para ser detective privado en España

La figura de los detectives privados tiene un aura de misterio a su alrededor, puesto que muchas personas los tratan como policías cuando lo cierto es que su trabajo no se parece en nada. Los ...
LEER MAS +Algeco Portugal: todo sobre el líder en construcción modular

La construcción modular es una de las formas actuales más prácticas, eficientes y sostenibles de instalar un espacio altamente funcional en tiempo récord. A menudo se emplea en ámbitos laborales, ...
LEER MAS +Quiénes somos y qué hacemos
Bienvenido a Subgurim.net, un espacio especializado en todo tipo de productos, desde artículos para el hogar hasta herramientas de bricolaje, salud o telefonía. En nuestro portal encontrarás opiniones y análisis realizados por especialistas, que te ayudarán a la hora de escoger productos con una buena relación calidad-precio y todas las prestaciones que buscas en cada situación. Y no solo eso, también contamos con artículos relacionados con sectores más diversos, como economía, contabilidad o finanzas, pudiendo así ofrecerte la máxima información al respecto.
También contamos con artículos centrados en el mundo del motor, garantizando comparativas exhaustivas y prácticas tanto para escoger el mejor producto como para aprender a sacarle el máximo partido. Gracias a nuestros colaboradores hemos podido preparar artículos extensos y detallados sobre productos tan variados como los pulimentos para coches, lo que es de vital importancia para todo conductor que se precie y quiera cuidar su vehículo al milímetro, además de otros tantos artículos sobre innovaciones tecnológicas relacionadas con nuevos sistemas, como el asistente de aparcamiento, entre otros. Como siempre, con la garantía de que toda la información que aportamos es fiable, está actualizada y revisada por especialistas.
Disponemos de varias categorías orientadas a facilitar tu búsqueda, pues nuestro objetivo es que puedas encontrar tanto la información como el producto que necesitas en cada momento de la forma más rápida y cómoda. En nuestra categoría Hogar, sin ir más lejos, podrás encontrar objetos, herramientas, dispositivos y otros útiles indispensables que te facilitarán la vida, tanto para interior como para exterior. Contamos con análisis expertos en múltiples artículos para el hogar, como sobrecolchones viscoelásticos, baterías de cocina o aspiradores potentes. Sea lo que sea lo que estás buscando, lo encontrarás en Subgurim.net.
Además, en nuestro portal no nos olvidamos de los más pequeños de la casa. Disponemos de un sinfín de artículos, consejos y comparativas orientadas a los niños y a sus padres, para que podáis encontrar los mejores productos para ellos sin tener que valorar opciones de baja calidad, desde prismáticos para niños hasta lámparas infantiles. Tanto si buscas algo para él o para que a ti te resulte más fácil darle los cuidados que necesita, échale un vistazo a nuestros artículos y encuentra lo que necesitas.